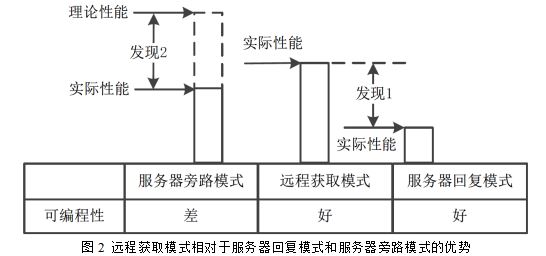
摘 要:本论文提出了一种新型的RDMA设计模式,涉及云存储系统的远程数据获取设计模式,通过该设计模式优化云数据中心的服务端,最终加速系统云存储系统,提高网络应用程序性能。 RDMA是一种直接存取远程内存的技术。RDMA 操作具有旁路特性,允许某台机器的CPU 能够直接读写其他远程机器的内存数据,而不需要该远程机器CPU 以及操作系统的任何参与。同时,RDMA 操作还具有数据零拷贝特性,在发送请求和接收请求的机器上,RDMA 操作能够避免数据在用户态空间和内核态空间之间的显式拷贝。由于具有旁路特性、数据零拷贝特性以及更加简单的协议栈,RDMA 相比软件层面实现的TCP/IP 协议具有更高的性能。 RPC 可以为上层系统隐藏消息通信的复杂性,给系统开发者提供良好的可编程性。几乎所有的RPC 机制都采用同一种架构。具体而言,在RPC 机制中,一个RPC调用包括以下三个步骤(如图5):(1)请求发送:客户端将调用函数以及相关的调用参数发送给服务器;(2)请求处理:客户端发送的请求得到处理,并产生相应的结果;(3)结果返回:请求处理得到的结果通过网络传输到客户端。 目前存在两种将RDMA 应用到云存储系统的设计模式:服务器回复模式和服务器旁路模式。服务器回复模式要求服务器负责处理客户端的请求,并将处理结果发送给客户端。该设计模式用RDMA 替换了传统的TCP/IP,但是不改变对上层系统提供的RPC 接口。因此,服务器回复模式具有很好的可编程性。但是,由于没有充分利用RDMA 的特性,服务器回复模式所能提供的性能是非常有限的。服务器旁路模式要求客户端通过RDMA 远程操作服务器内存的数据,直接完成请求,而服务器不参与请求的处理。由于利用RDMA 的旁路特性降低了服务器CPU 的开销,服务器旁路模式相比服务器回复模式会带来将近一倍的性能提升。但是,服务器旁路模式却损失了可编程性,它必须依赖系统开发者设计特殊的数据结构和算法,并对原有系统进行较大范围的改动。因此,服务器回复模式和服务器旁路模式给云存储系统开发者带来了一个设计难题,让其不得不在可编程性和性能之间做选择。 发现1: RDMA 网卡的性能非对称性。性能非对称性产生的原因是在硬件设计上,RDMA网卡发送RDMA 操作(RDMA 输出操作)产生的开销和接收RDMA 操作(RDMA 输入操作)产生的开销是不一样的,前者要远远大于后者。服务器回复模式依赖服务器通过RDMA 输出写操作将结果返回给客户端,这导致服务器很快就用满了RDMA 输出操作的IOPS,而此时RDMA 输入操作的IOPS 还远远未达到性能瓶颈。
发现2: RDMA 网卡的性能非对称性。服务器旁路模式在期望获得的性能和实际获得的性能之间存在差距。由于服务器的CPU 在处理请求的过程中被旁路了,客户端必须使用更多数目的RDMA 操作来解决数据冲突。这会导致系统实际性能的降低,尤其是在冲突更加严重的写密集数据集中。 发现3: RDMA 网卡的性能相似性。硬件设计原则决定了RDMA 网卡具有性能相似性,而且性能相似性主要体现在RDMA 输入操作上:在某个性能相似区间内,RDMA 网卡的RDMA 输入操作性能不取决于数据的大小,而是呈现出比较稳定的数值。 本论文提出了远程获取模式。作为一种新型的RDMA 设计模式,其不仅能支持传统的RPC 接口让系统不需要经过大规模修改就能使用,而且可以提供比服务器回复模式和服务器旁路模式更好的性能。 远程获取模式采用了两个关键的设计选择:第一个设计选择是服务器应该负责处理客户端的请求,这样不仅可以提供很好的可编程性,方便上层系统简单地使用,而且可以避免客户端对冲突的处理;第二个设计选择是请求处理结果应该由客户端通过RDMA 读操作来远程获取,而不是由服务器通过RDMA 写操作来发送。 1. 客户端调用client_send (表1)接口将请求通过RDMA 写操作发送到服务器的内存中 2. 服务器通过调用server_recv (表1)接口从本地内存中获得客户端请求,并处理这些请求。
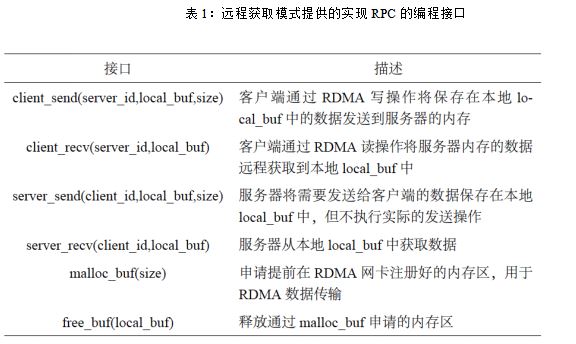
在远程获取模式中,服务器在处理完请求后并不将结果发回给客户端。相反,服务器调用的server_send 接口仅将结果保存在本地的内存中。当客户端调用client_recv 接口时,client_recv 接口会通过RDMA 读操作将结果从服务器的内存远程获取到本地内存中。 服务器和客户端都要维护一定数量的请求内存区和结果内存区,以用来进行请求数据和结果数据的交换。这些内存区必须要提前在RDMA 网卡中进行注册,才能被RDMA 操作利用。因此,远程获取模式还提供了两个内存操作相关的接口:malloc_buf 和free_buf(如表1所示)。这两个接口分别被用来申请和释放在RDMA 网卡上已经注册好的内存区。无论是服务器还是客户端,它们在用RDMA 传输数据之前需要将对应的数据存放在通过malloc_buf 接口申请的内存区中,这样还能保证远程获取模式能够利用RDMA 的数据零拷贝特性。如图1所示,每个内存区都有一块头部信息,该头部信息不仅含有请求是否已经达到或者结果是否已经准备就绪的状态信息,还包含请求数据或者结果数据的大小。另外,每个结果内存区的头部信息还含有一个2字节大小的处理时间变量,用来保存服务器处理对应请求所花费的时间。该变量被客户端用来判断服务器负载的高低。
如图2所示,和服务器回复模式以及服务器旁路模式相比,远程获取模式既能保留发现1和发现2 涉及到的优点,又能避免发现1 和发现2 涉及到的缺点。首先,和服务器回复模式一样,远程获取模式也依赖服务器来处理请求。因此,传统RPC 接口可以很容易地实现并提供给上层系统使用,这保留了服务器回复模式可编程性好的优点。在远程获取模式中,客户端不需要再消耗多个RDMA 操作来完成一个请求,也不需要关注解决冲突的问题,这避免了服务器旁路模式的缺点。其次,远程获取模式不要求服务器将CPU 资源浪费在通过网络将结果发回给客户端的操作上,这一点是和传统的认知有很大不同的。远程获取模式只要求服务器将处理完的结果缓存在本地的内存中,并要求客户端通过RDMA 读操作主动从服务器内存中获取结果。因此,远程获取模式就不会受到服务器RDMA 网卡在RDMA 输出操作上性能瓶颈的限制,而且能够利用服务器RDMA 网卡高性能的RDMA 输入操作。这保留了服务器旁路模式的优点,避免了服务器回复模式的缺点。通过充分利用RDMA 网卡的性能非对称性,远程获取模式获得了比服务器回复模式和服务器旁路模式更高的性能。 实现远程获取模式必须要解决两个问题:第一个问题是客户端应该在什么时候从服务器获取结果,第二个问题是客户端一次应该获取的结果数据为多大。本论文分别提出来结果数据混合传输机制和RDMA网卡性能特征提取机制来解决相应问题。 结果数据混合传输机制:该机制首先会采用不间断获取方式来将结果数据从服务器传输到客户端,但是,如果其监测到不间断获取方式所需要的RDMA 读操作数目大于一定的阈值(该阈值即为T)时,它会自动切换到服务器回复方式。服务器回复方式即为服务器回复模式采用的数据传输方式:服务器通过RDMA 写操作将结果主动发回给客户端。云盘结果数据混合传输机制能够智能地在不间断获取方式和服务器回复方式之间做切换,以在访问延迟、IOPS 和客户端CPU 使用率之间不断地做权衡。T的选择需要依据具体的硬件配置情况,包括RDMA 网卡的配置、机器CPU 的配置等。 RDMA网卡性能特征提取机制:该机制能够自动根据RDMA 网卡的硬件特性和系统结果大小的范围设置FS,给系统提供最优的性能。对于某个特定的系统,远程获取模式会提前将该系统运行一段时间,并收集该系统中每个RPC 调用的结果大小。远程获取模式还会提前构建好FS的集合,集合中含有所有可能的FS 数值,每个数值对应的IOPS 是远程获取模式根据RDMA 网卡硬件特性通过一次测试而自动获得的。然后,对于FS 集合中的每个数值,远程获取模式会计算在系统提供的所有结果大小的情况下,该数值让系统获得的性能。能够让系统获得的最大化性能的数值即为该系统对应的最优FS。 为了验证远程获取模式对上层系统的有效性和良好的可编程性,作者基于远程获取模式设计并实现了内存数据库Jakiro。Jakiro 包含两个主要的模块:一个是用来保存key-value 对的内存数据结构,另一个是用来完成RPC 调用的通信协议。Jakiro 内存数据结构的设计独立于远程获取模式,华为网盘官网手机版而通信协议的设计是使用远程获取模式的。 在Jakiro 中,服务器向客户端暴露传统的RPC 接口,客户端通过调用这些RPC 接口完成key-value 对的读或者写操作。当客户端调用RPC 时,通信协议负责完成这些RPC调用,并向客户端返回调用结果。具体来说,通信协议的工作流程如下: 1. 发送请求。当客户端进行RPC 调用后,客户端线程会对调用的函数及其参数进行序列化,并将序列化后的数据存放到通过malloc_buf 申请的请求内存区中。然后,客户端线程调用client_send 接口发送请求。client_send 会准备好请求内存区的头部信息,并将一个1 字节大小的尾部变量(变量的值设为1)追加在请求数据的尾部。当这些操作都完成后,client_send 调用RDMA写操作将请求发送到服务器中对应的请求内存区中。在请求数据的尾部再加一个尾部变量是必要的,因为当服务器检测到尾部变量变为1 时,就说明客户端发送请求的操作已经全部完成了。 2. 处理请求。服务器线程会周期性地调用server_recv 接口来获得来自客户端的请求。当server_recv 检测到请求内存区头部的状态信息已经就绪并且请求数据末端的尾部变量变为1 时,它会将请求返回给服务器线程。服务器线程拿到请求后,会反序列化请求具体调用的函数以及相应的参数,并在它所管理的内存数据结构上执行该请求。当请求执行完成后,服务器线程对执行结果进行序列化,将序列化后的数据存放到通过malloc_buf 申请的结果内存区中,并调用server_send 接口。server_send 准备好结果内存区的头部信息后返回。 3. 传输结果。在将请求发送给服务器后,客户端线程就调用client_recv 接口获取请求的结果。腾讯微盘网页版登录client_recv 会使用不间断获取方式或者服务器回复方式将结果从服务器的内存传输到客户端的内存,并将结果返回给客户端线程。客户端线程对结果进行反序列化,并将结果最终返回给上层系统。 从上述可以看出,Jakiro 通信协议在远程获取模式上的实现和在传统TCP/IP 接口上的实现几乎没有大的差别,远程获取模式对于Jakiro 通信协议来说只是一个掩盖底层复杂性的通信库。这也进一步证明了远程获取模式具有很好的可编程性。 Jakiro中远程获取模式中负责RDMA传输的通信库采用的是Mellanox 公司提供的rdmacm 和ibverbs 通信库。在Jakiro 中,服务器线程和客户端线程直接访问其机器上的内存区和RDMA 网卡,以获取消息(请求或结果)发送/接收的事件。同时,每个服务器线程要负责所有有关数据序列化/反序列化、数据发送/接收以及请求处理的相关工作。 本论文在远程获取模式下,解决了两个问题:第一个问题是客户端应该在什么时候从服务器获取结果,第二个问题是客户端一次应该获取的结果数据为多大。 client_id 表示某个客户端,用RPC_id 表示某种类型的RPC 调用,同时同一类型的RPC 调用在执行时间的数量级上差别不大。那么,对于每对?client_id,RPC_id?,客户端和服务器都会维护一个传输方式标志mode_flag,该标志用来表示远程获取模式目前正在使用的传输方式。mode_flag 只能被其对应的客户端来修改,该客户端通过本地的内存写修改本地维护的mode_flag,通过RDMA 写操作远程修改服务器维护的mode_flag。在系统刚启动时,mode_flag 被设置为不间断获取方式对应的标志。因此,客户端会不停地通过RDMA 读操作从服务器内存中获取结果。如果客户端连续5 次的RDMA 读操作都没有成功地将结果获取到本地,说明服务器处理该请求的时间比较长,那么客户端就会将本地和服务器的mode_flag 更新成服务器回复方式对应的标志。在标志更新完成后,客户端就不再调用RDMA 读操作,而是等待结果由服务器通过RDMA 写操作发送回来。如果客户端当前处于服务器回复方式,它会检测结果内存区头部信息中的处理时间变量。当该变量表示的服务器处理请求时间变短时,客户端会修改本地和服务器的mode_flag,将其更新成不间断获取方式。 需要说明的是,由于客户端更新服务器的mode_flag 用的是RDMA 操作,而RDMA 操作的过程是服务器的CPU 无法知晓的,因此,当mode_flag 对应的是不间断获取方式的状态时,客户端更新mode_flag 时会存在客户端切换到了服务器回复方式、而服务器仍停留在不间断获取方式的可能。此时,客户端不会去获取结果,服务器也不会主动将结果发回,客户端和服务器之间存在着一种死锁状态,整个系统无法继续向前执行。作者通过让服务器周期性地检测mode_flag 来解决这个问题。当服务器为客户端准备好结果后,会首先检测对应的mode_flag,并根据mode_flag 的状态来执行对应的数据传输方式。但是此时执行的数据传输方式并不一定是客户端要求的数据传输方式。服务器在执行完传输方式后,每隔1 微秒会再检测mode_flag 的状态,如果发现mode_flag 的状态有改变,就执行新的数据传输方式。这样就打破了mode_flag 切换时可能带来的死锁状态。当mode_flag 对应的是服务器回复方式时,客户端更新mode_flag 会存在客户端切换到不间断获取方式、而服务器仍停留在服务器回复方式的可能。此时,结果会传输到客户端两次,一次是客户端主动获取的,一次是服务器主动发回的,但这不会影响结果正确地从服务器传输到客户端。 另外,mode_flag 的改变还需要考虑长尾(long-tail)现象。长尾现象指的是在许多相同类型的调用之中,会有极少数的调用出现执行时间很长的情况。长尾现象会使客户端无法通过不间断获取方式成功获取结果,导致结果数据混合传输机制进行不必要的方式切换。为了解决这个问题,结果数据混合传输机制只有当连续N个请求(N 1)个RPC 调用都经历了T 次RDMA 读操作而没有成功获取到结果时,才会让客户端和服务器从不间断获取方式切换到服务器回复方式。否则,如果只有1 个RPC 调用经历了Ttry 次RDMA 读操作而没有成功获取到结果,那么就不进行传输方式的切换。实验结果显示,当客户端请求不会带来很大的执行负载时,只有0.2% 的RPC 调用会经历长尾现象,因而连续两个甚至多个RPC 调用都经历长尾现象的概率极低。 在远程获取模式中将结果紧邻着头部信息存储在结果内存区中,并为每个客户端设置一个远程获取结果大小的变量,记为FS。每个客户端只调用一次RDMA 读操作,将结果内存区中的头部信息以及FS 大小的结果数据一同获取到本地。然后客户端会检测头部信息中记录的结果数据的实际大小,只有当实际大小大于FS 时,客户端才需要再发送一次RDMA 读操作将余下的数据取回。这种方式可以大幅降低完成一次RPC 调用所需要的RDMA 读操作数目,尤其是当结果数据通常都比较小的情况下。 FS 的设置对系统性能的影响十分显著,因为它决定了远程获取结果所需要的RDMA 操作数目。例如,假设某个系统的RPC 调用结果的大小在257 字节到512 字节之间。如果将FS 设置为256 字节,那么客户端就至少需要2 次RDMA读操作才能将RPC 调用的结果获取到本地,这会浪费RDMA 网卡的IOPS 资源,造成系统性能的下降。如果将FS 设置为512 字节,那么所有的结果都可以通过一次RDMA 读操作就可以获取到客户端本地。因此,即便RDMA 网卡的RDMA输入读操作在512 字节上的IOPS(7.34MOPS)要低于其在256 字节上的IOPS(10.79MOPS),但是将FS 设为512 字节能够给系统提供5.41MOPS 的性能,而将FS 设为256 字节却只能给系统提供3.75MOPS 的性能。
对于某个特定的系统,远程获取模式会提前将该系统运行一段时间,并收集该系统中每个RPC 调用的结果大小。远程获取模式还会提前构建好FS 的集合,集合中含有所有可能的FS 数值,每个数值对应的IOPS 是远程获取模式根据RDMA 网卡硬件特性通过一次测试而自动获得的。然后,对于FS 集合中的每个数值,远程获取模式会计算在系统提供的所有结果大小的情况下,该数值让系统获得的性能。能够让系统获得的最大化性能的数值即为该系统对应的最优FS。当然,FS 集合中的数值并不是无限多的,而是有上限和下限的。集合中的上限和下限也是根据RDMA 网卡的硬件特性设定的。例如,对于作者使用的测试集群来说,FS 集合的下限设置为256 字节,因为小于256 字节的FS 不会提高客户端远程获取结果的性能(如图3所示)。
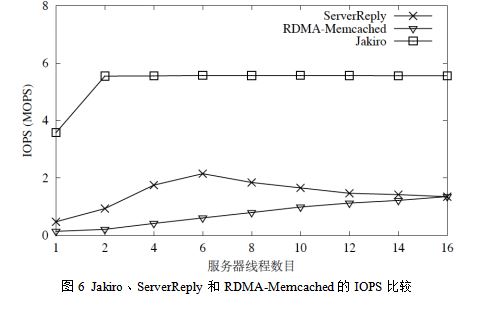
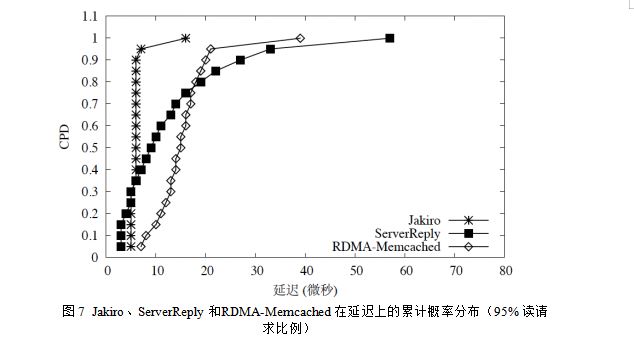
因为RDMA 网卡通过RDMA 操作传输数据时无法避免额外的硬件开销(参见图4)。同时,FS 集合的上限设置为1024字节,因为大于1024 字节的FS 也不会提高客户端远程获取结果的性能,云存储因为对RDMA 网卡来说,此时成为性能瓶颈的是网络带宽而不是IOPS。当网络带宽成为性能瓶颈时,影响性能的主要是传输数据的大小,而不是RDMA 网卡上额外的硬件开销。 1. 测试数据集:作者选择测试数据集中的key 的大小为16 字节,value 的大小为32 字节。该测试数据集中key-value 对的大小和实际数据中心里运行的内存数据库的key-value 对大小类似。对于key 均匀分布测试集,作者使用YCSB基准测试程序均匀地产生key-value对。对于key 非均匀分布测试集,聚美优品注销作者使用YCSB 并依据参数为.99 的Zipf分布产生key-value 对。实验总共产生了1.28 亿个key-value 对,每个key-value 对被操作20 次。对于value 大小为32 字节的测试集来说,远程获取模式将FS 的大小设为256 字节。 2. 对比系统选择:作者将Jakiro 和两个采用服务器回复模式的内存key-value 数据库对比。第一个内存key-value 数据库记做ServerReply,它的内存数据结构和Jakiro 的内存数据结构一模一样,唯一和Jakiro 不一样的就是它完全采用服务器回复模式来传输结果。第二个内存key-value 数据库记做RDMA-Memcached,它是由俄亥俄州立大学的研究人员开发的利用RDMA 提升性能的Memcached。 3. 吞吐量比较:图6展示了当value 大小为32 字节时,Jakiro、ServerReply 和RDMAMemcached的IOPS。Jakiro 的IOPS 峰值为5.5 MOPS,该数值恰好为服务器RDMA 网卡的RDMA 输入读操作IOPS 峰值的一半(11.2MOPS,如图6所示)。该结果也证明了远程获取模式为Jakiro 设置的远程获取结果大小FS(256 字节)是最优的。对Jakiro 来说,完成一次key-value 对的RPC 调用平均只需要2.005 次RDMA 操作:一是客户端通过一次RDMA 写操作将请求发送给服务器,二是客户端通过1.005 次RDMA 读操作将结果从服务器的内存中远程获取到本地。256字节的FS 几乎没有浪费系统中的网络资源。 需要说明的是,当Jakiro 的客户端机器启动更多数目的客户端线程时,Jakiro的IOPS 会缓慢下降,如图3.11所示。这是因为客户端机器向服务器发送的RDMA读写操作对客户端机器的RDMA 网卡来说是输出的,如果客户端机器上启动的客户端线程数目增加,它每秒能够向服务器发送的RDMA 操作数由于可扩展性的问题就会下降。但是,即使在每台客户端机器上启动16 个线 个线程),Jakiro 的IOPS 仍然能够达到3.1 MOPS。这个IOPS 值还是会高于ServerReply 和RDMA-Memcached 的IOPS 峰值。 4. 延迟的比较:当value 大小为32 字节时,Jakiro 的key-value 对读写请求的平均延迟为5.78微秒,该数值要比ServerReply 的平均延迟(12.06 微秒)优108%,比RDMAMemcached的平均延迟(14.76 微秒)优155%。图7展示了这三个系统在IOPS达到峰值时,各自延迟的累计概率分布(Cumulative Probability Distribution,简称CPD)。从该图可以观察到,ServerReply 有15% 的RPC 调用的延迟要比Jakiro 的延迟低。造成这种现象的原因有两点:(1)单个RDMA 写操作的延迟要比单个RDMA 读操作的延迟低。从RDMA 网卡硬件层面上来分析,RDMA 写操作所需要的状态和硬件操作比RDMA 读操作的要少,因此其性能要优于RDMA 读操作。
另外,本论文提出的结果数据混合传输机制帮助Jakiro 很好地权衡了延迟和IOPS。在Jakiro 中,一些延迟很高(15 微秒到17 微秒)的RPC 调用需要4 到8 次RDMA 操作来完成请求的发送和结果的获取,而具有正常延迟的RPC 调用只需要2 次RDMA 操作就能完成。但是,需要多于2 次RDMA 操作来完成的RPC 调用只占所有请求的0.2%,并且没有出现连续两个RPC 调用都无法在5 次RDMA 读操作内成功获取结果的情况。因此,在Jakiro 中,只需将请求的个数N设置为2就能避免远程获取模式在不间断获取方式和服务器回复方式之间进行不必要的切换,并在提供低延迟的前提下保证5.5MOPS 的IOPS 峰值。开发者可以根据系统实际的运行情况设置N的大小,以决定结果传输方式的切换时间。 云存储系统中RPC的执行决定着整个系统的性能,本文通过利用RDMA技术来优化云存储设计模式,最终达到较高的吞吐量,这种方式对于Web应用的核心组件Key-Value Store及其优化极其友好。因此该设计模式有助于提高云存储系统的整体性能,并优化基于网页端的服务。
“2018新闻传播学院院长论坛”11月10日在厦门大学举行。人民日报社副总编辑卢新宁,福建省委常委、宣传部部长、秘书长梁建勇,厦门大学党委书记张彦,教育部高等教育司司长吴岩等与会并致辞。
由国家互联网信息办公室和浙江省人民政府共同主办的第五届世界互联网大会于11月7日至9日在乌镇召开。本届大会以“创造互信共治的数字世界——携手共建网络空间命运共同体”为主题。 网盘会员到 2019年01月22日 23:18:48 |


Archiver|手机版|
百度云会员 百度云会员账号 百度网盘会员账号 百度云会员分享

GMT+8, 2025-12-18 09:22 , Processed in 0.063384 second(s), 16 queries .